Tumblr Communities Scraper
Extract community names, member counts, and tags from Tumblr community browse and search pages. Powered by Tumblr Scraper.
tumblr-communities-scraper
Open in Apify →

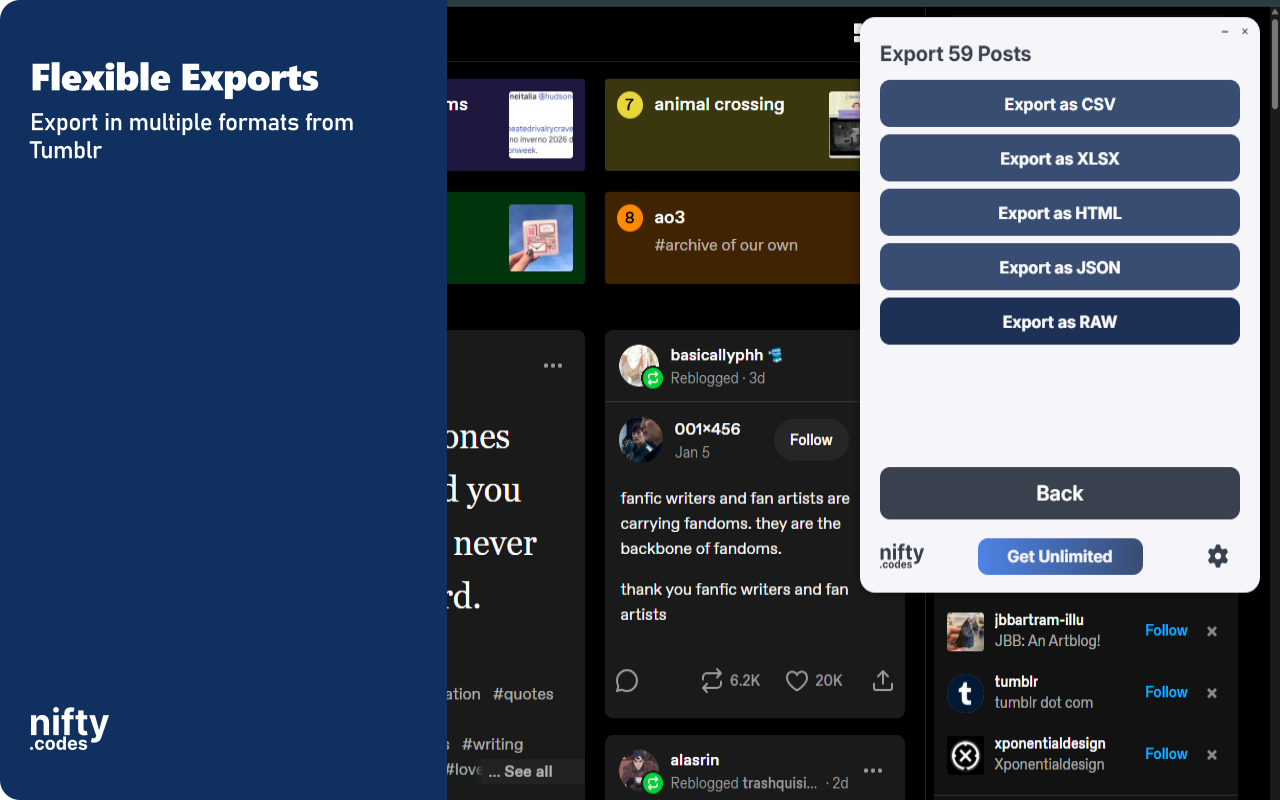
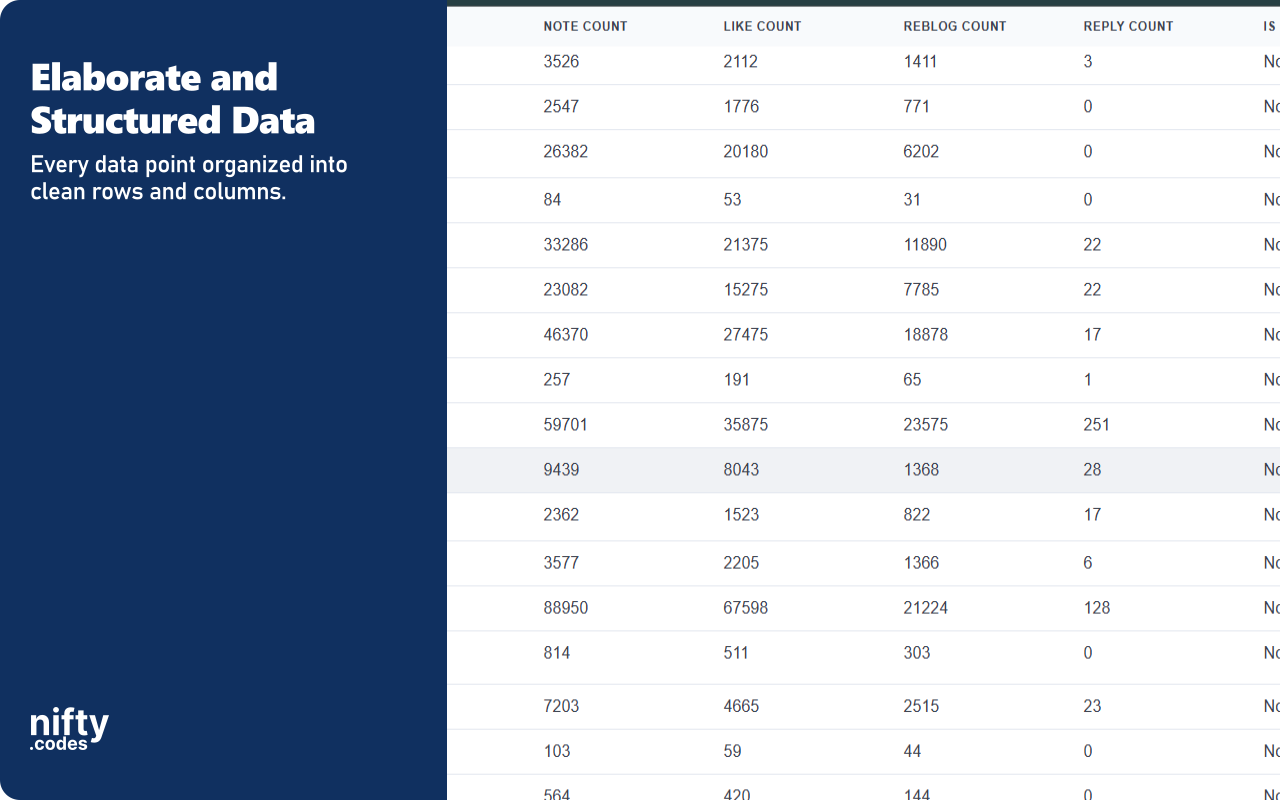
Tumblr Scraper: Collect replies, likes, members & community details from Tumblr. Export to CSV, JSON, XLSX.
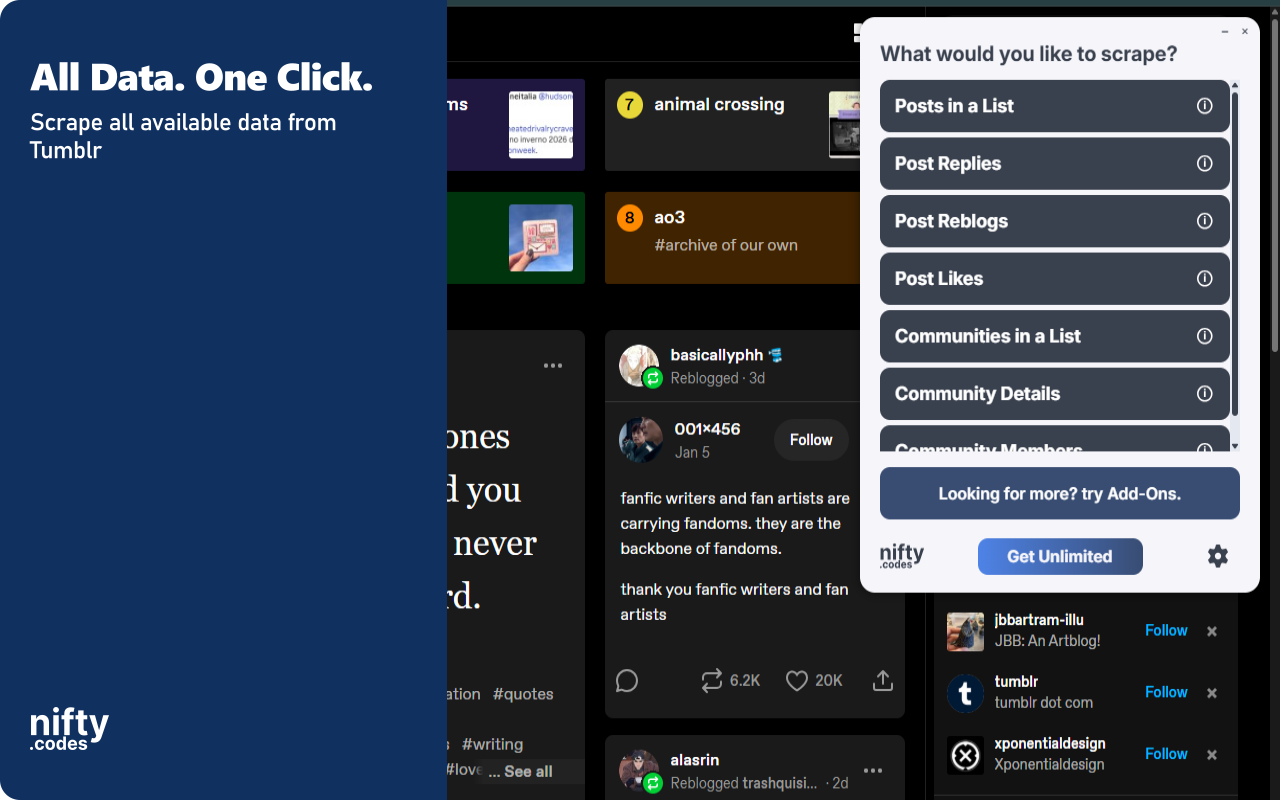
Open the page, pick one of these, and start collecting.
Optional tools that extend what this scraper can do.
Open and scrape multiple URLs in one go. Add URLs manually or auto-collect them from a list page, then batch-process and export all results.
Track changes on any page and get notified instantly. Set conditions on fields you care about and receive alerts via webhook or ntfy.sh when something changes.
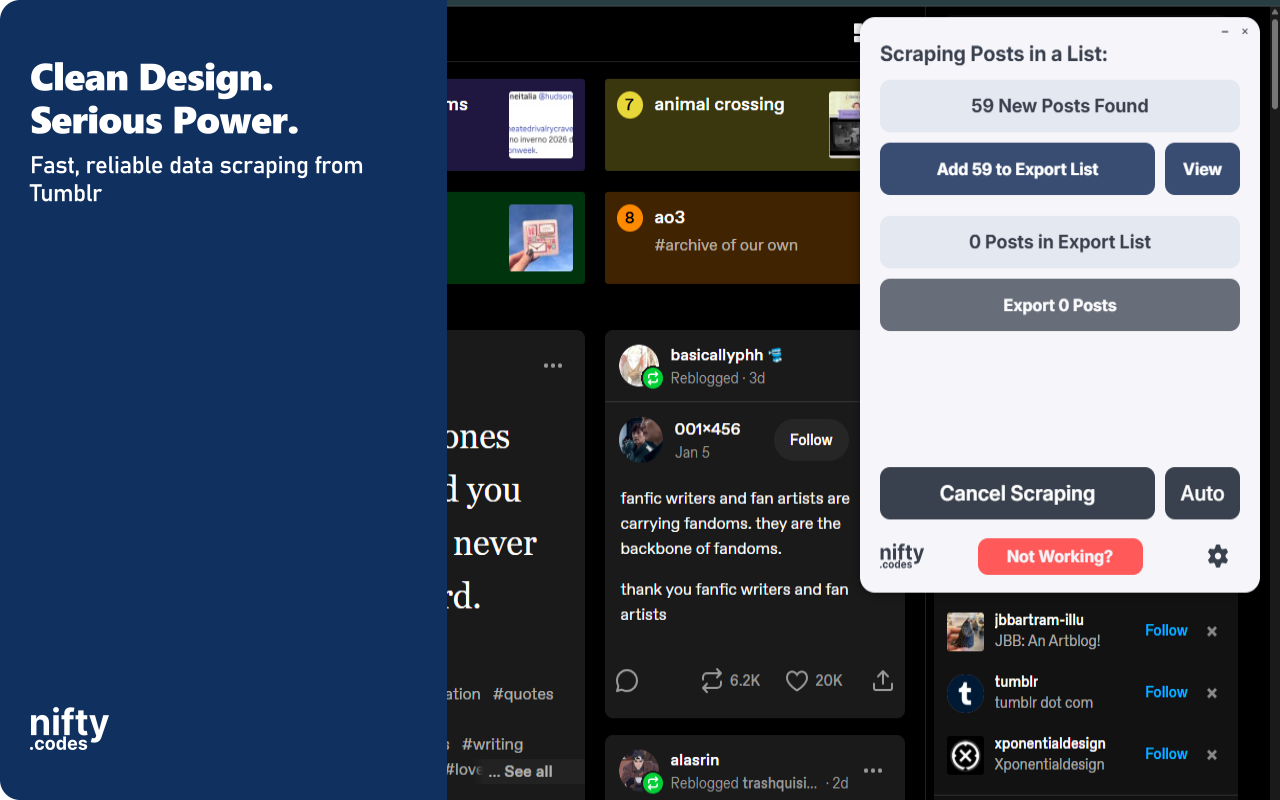
Open the page you want to scrape, select the type of data you need from the list, and that's it. It just works. If you want to take it further, you can with customizations, webhooks, add-ons, and a lot more.
Very. We have 50+ scrapers and each one goes through a regular monthly testing cycle. On top of that, we take bug reports seriously and most issues are fixed within 48 hours.
This scraper works on tumblr.com.
Yes, we have a Page Watcher tool built for exactly that. It can track new results appearing in a list, or watch specific values like price or likes for any changes.
It's free to use with limits. To unlock everything, it's $9.99/month.
We don't typically offer free trials. There are real costs behind keeping everything maintained and improving. That said, feel free to reach out through the Contact form. Sometimes we're in a good mood :)
Prefer the cloud? Run Tumblr Scraper through ready-made Apify actors.
Extract community names, member counts, and tags from Tumblr community browse and search pages. Powered by Tumblr Scraper.
Extract community metadata including member counts, online status, post counts, and creation dates from Tumblr community pages. Powered by Tumblr Scraper.
Extract Tumblr posts from blog feeds, tag searches, and explore pages with engagement metrics and media metadata. Powered by Tumblr Scraper.
Updates and fixes, most recent first.
Find the one for the site you use next.